reader comments
50 with 36 posters participating, including story author
On Wednesday, OpenAI released a new open source AI model called Whisper that recognizes and translates audio at a level that approaches human recognition ability. It can transcribe interviews, podcasts, conversations, and more.
OpenAI trained Whisper on 680,000 hours of audio data and matching transcripts in 98 languages collected from the web. According to OpenAI, this open-collection approach has led to “improved robustness to accents, background noise, and technical language.” It can also detect the spoken language and translate it to English.
OpenAI describes Whisper as an encoder-decoder transformer, a type of neural network that can use context gleaned from input data to learn associations that can then be translated into the model’s output. OpenAI presents this overview of Whisper’s operation:
Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
By open-sourcing Whisper, OpenAI hopes to introduce a new foundation model that others can build on in the future to improve speech processing and accessibility tools. OpenAI has a significant track record on this front. In January 2021, OpenAI released CLIP, an open source computer vision model that arguably ignited the recent era of rapidly progressing image synthesis technology such as DALL-E 2 and Stable Diffusion.
available on GitHub, and we fed it multiple samples, including a podcast episode and a particularly difficult-to-understand section of audio taken from a telephone interview. Although it took some time while running through a standard Intel desktop CPU (the technology doesn’t work in real time yet), Whisper did a good job of transcribing the audio into text through the demonstration Python program—far better than some AI-powered audio transcription services we have tried in the past.
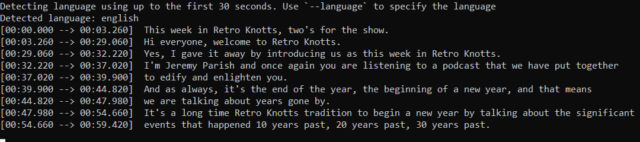
With the proper setup, Whisper could easily be used to transcribe interviews, podcasts, and potentially translate podcasts produced in non-English languages to English on your machine—for free. That’s a potent combination that might eventually disrupt the transcription industry.
As with almost every major new AI model these days, Whisper brings positive advantages and the potential for misuse. On Whisper’s model card (under the “Broader Implications” section), OpenAI warns that Whisper could be used to automate surveillance or identify individual speakers in a conversation, but the company hopes it will be used “primarily for beneficial purposes.”






