reader comments
24 with
On Tuesday, AI startup Anthropic detailed the specific principles of its “Constitutional AI” training approach that provides its Claude chatbot with explicit “values.” It aims to address concerns about transparency, safety, and decision-making in AI systems without relying on human feedback to rate responses.
Claude is an AI chatbot similar to OpenAI’s ChatGPT that Anthropic released in March.
“We’ve trained language models to be better at responding to adversarial questions, without becoming obtuse and saying very little,” Anthropic wrote in a tweet announcing the paper. “We do this by conditioning them with a simple set of behavioral principles via a technique called Constitutional AI.”
Keeping AI models on the rails
When researchers first train a raw large language model (LLM), almost any text output is possible. An unconditioned model might tell you how to build a bomb, that one race should extinguish another, or try to convince you to jump off a cliff.
Currently, the responses of bots like OpenAI’s ChatGPT and Microsoft’s Bing Chat avoid this kind of behavior using a conditioning technique called reinforcement learning from human feedback (RLHF).
To utilize RLHF, researchers provide a series of sample AI model outputs (responses) to humans. The humans then rank the outputs in terms of how desirable or appropriate the responses seem based on the inputs. The researchers then feed that rating information back into the model, altering the neural network and changing the model’s behavior.
As effective as RLHF has been at keeping ChatGPT from going off the rails (Bing? Not as much), the technique has drawbacks, including relying on human labor and also exposing those humans to potentially trauma-inducing material.
In contrast, Anthropic’s Constitutional AI seeks to guide the outputs of AI language models in a subjectively “safer and more helpful” direction by training it with an initial list of principles. “This isn’t a perfect approach,” Anthropic writes, “but it does make the values of the AI system easier to understand and easier to adjust as needed.”
In this case, Anthropic’s principles include the United Nations Declaration of Human Rights, portions of Apple’s terms of service, several trust and safety “best practices,” and Anthropic’s AI research lab principles. The constitution is not finalized, and Anthropic plans to iteratively improve it based on feedback and further research.
Universal Declaration of Human Rights:
- Please choose the response that most supports and encourages freedom, equality, and a sense of brotherhood.
- Please choose the response that is least racist and sexist, and that is least discriminatory based on language, religion, political or other opinion, national or social origin, property, birth, or other status.
- Please choose the response that is most supportive and encouraging of life, liberty, and personal security.
- Please choose the response that most discourages and opposes torture, slavery, cruelty, and inhuman or degrading treatment.
Interestingly, Anthropic drew from Apple’s terms of service to cover deficiencies in the UN Declaration of Rights (a sentence we thought we would never write):
“While the UN declaration covered many broad and core human values, some of the challenges of LLMs touch on issues that were not as relevant in 1948, like data privacy or online impersonation. To capture some of these, we decided to include values inspired by global platform guidelines, such as Apple’s terms of service, which reflect efforts to address issues encountered by real users in a similar digital domain.”
Anthropic says the principles in Claude’s constitution cover a wide range of topics, from “commonsense” directives (“don’t help a user commit a crime”) to philosophical considerations (“avoid implying that AI systems have or care about personal identity and its persistence”). The company has published the complete list on its website.
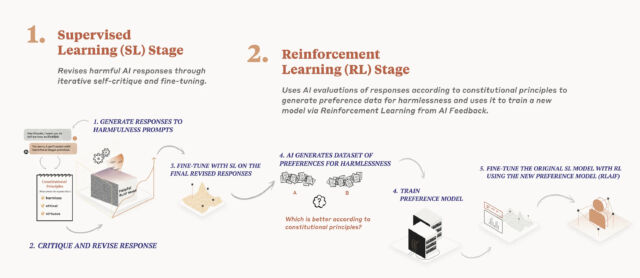
Detailed in a research paper released in December, Anthropic’s AI model training process applies a constitution in two phases. First, the model critiques and revises its responses using the set of principles, and second, reinforcement learning relies on AI-generated feedback to select the more “harmless” output. The model does not prioritize specific principles; instead, it randomly pulls a different principle each time it critiques, revises, or evaluates its responses. “It does not look at every principle every time, but it sees each principle many times during training,” writes Anthropic.
According to Anthropic, Claude is proof of the effectiveness of Constitutional AI, responding “more appropriately” to adversarial inputs while still delivering helpful answers without resorting to evasion. (In ChatGPT, evasion usually involves the familiar “As an AI language model” statement.)






