reader comments
31 with 26 posters participating
In response to controversy over image synthesis models learning from artists’ images scraped from the Internet without consent—and potentially replicating their artistic styles—a group of artists has released a new website that allows anyone to see if their artwork has been used to train AI.
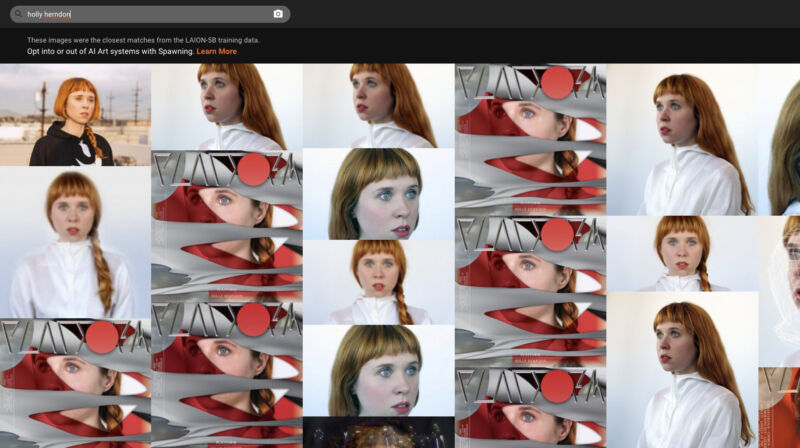
The website “Have I Been Trained?” taps into the LAION-5B training data used to train Stable Diffusion and Google’s Imagen AI models, among others. To build LAION-5B, bots directed by a group of AI researchers crawled billions of websites, including large repositories of artwork at DeviantArt, ArtStation, Pinterest, Getty Images, and more. Along the way, LAION collected millions of images from artists and copyright holders without consultation, which irritated some artists.
When visiting the Have I Been Trained? website, which is run by a group of artists called Spawning, users can search the data set by text (such as an artist’s name) or by an image they upload. They will see image results alongside caption data linked to each image. It is similar to an earlier LAION-5B search tool created by Romain Beaumont and a recent effort by Andy Baio and Simon Willison, but with a slick interface and the ability to do a reverse image search.
Any matches in the results mean that the image could have potentially been used to train AI image generators and might still be used to train tomorrow’s image synthesis models. AI artists can also use the results to guide more accurate prompts.
Spawning’s website is part of the group’s goal to establish norms around obtaining consent from artists to use their images in future AI training efforts, including developing tools that aim to let artists opt in or out of AI training.

As mentioned above, image synthesis models (ISMs) like Stable Diffusion learn to generate images by analyzing millions of images scraped from the Internet. These images are valuable for training purposes because they have labels (often called metadata) attached, such as captions and alt text. The link between this metadata and the images lets ISMs learn associations between words (such as artist names) and image styles.
When you type in a prompt like, “a painting of a cat by Leonardo DaVinci,” the ISM references what it knows about every word in that phrase, including images of cats and DaVinci’s paintings, and how the pixels in those images are usually arranged in relationship to each other. Then it composes a result that combines that knowledge into a new image. If a model is trained properly, it will never return an exact copy of an image used to train it, but some images might be similar in style or composition to the source material.
It would be impractical to pay humans to manually write descriptions of billions of images for an image data set (although it has been attempted at a much smaller scale), so all the “free” image data on the Internet is a tempting target for AI researchers. They don’t seek consent because the practice appears to be legal due to US court decisions on Internet data scraping. But one recurring theme in AI news stories is that deep learning can find new ways to use public data that wasn’t previously anticipated—and do it in ways that might violate privacy, social norms, or community ethics even if the method is technically legal.
It’s worth noting that people using AI image generators usually reference artists (usually more than one at a time) to blend artistic styles into something new and not in a quest to commit copyright infringement or nefariously imitate artists. Even so, some groups like Spawning feel that consent should always be part of the equation—especially as we venture into this uncharted, rapidly developing territory.





