
reader comments
76 with
Imagine typing “dramatic intro music” and hearing a soaring symphony or writing “creepy footsteps” and getting high-quality sound effects. That’s the promise of Stable Audio, a text-to-audio AI model announced Wednesday by Stability AI that can synthesize music or sounds from written descriptions. Before long, similar technology may challenge musicians for their jobs.
If you’ll recall, Stability AI is the company that helped fund the creation of Stable Diffusion, a latent diffusion image synthesis model released in August 2022. Not content to limit itself to generating images, the company branched out into audio by backing Harmonai, an AI lab that launched music generator Dance Diffusion in September.
Now Stability and Harmonai want to break into commercial AI audio production with Stable Audio. Judging by production samples, it seems like a significant audio quality upgrade from previous AI audio generators we’ve seen.
On its promotional page, Stability provides examples of the AI model in action with prompts like “epic trailer music intense tribal percussion and brass” and “lofi hip hop beat melodic chillhop 85 bpm.” It also offers samples of sound effects generated using Stable Audio, such as an airline pilot speaking over an intercom and people talking in a busy restaurant.
To train its model, Stability partnered with stock music provider AudioSparx and licensed a data set “consisting of over 800,000 audio files containing music, sound effects, and single-instrument stems, as well as corresponding text metadata.” After feeding 19,500 hours of audio into the model, Stable Audio knows how to imitate certain sounds it has heard on command because the sounds have been associated with text descriptions of them within its neural network.
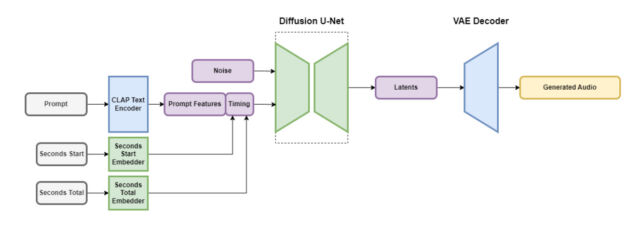
Stable Audio contains several parts that work together to create customized audio quickly. One part shrinks the audio file down in a way that keeps its important features while removing unnecessary noise. This makes the system both faster to teach and quicker at creating new audio. Another part uses text (metadata descriptions of the music and sounds) to help guide what kind of audio is generated.
Nvidia A100 GPU. The A100 is a beefy data center GPU designed for AI use, and it’s far more capable than a typical desktop gaming GPU.
As mentioned, Stable Audio isn’t the first music generator based on latent diffusion techniques. Last December, we covered Riffusion, a hobbyist take on an audio version of Stable Diffusion, though its resulting generations were far from Stable Audio’s samples in quality. In January, Google released MusicLM, an AI music generator for 24 kHz audio, and Meta launched a suite of open source audio tools (including a text-to-music generator) called AudioCraft in August. Now, with 44.1 kHz stereo audio, Stable Diffusion is upping the ante.
Stability says Stable Audio will be available in a free tier and a $12 monthly Pro plan. With the free option, users can generate up to 20 tracks per month, each with a maximum length of 20 seconds. The Pro plan expands these limits, allowing for 500 track generations per month and track lengths of up to 90 seconds. Future Stability releases are expected to include open source models based on the Stable Audio architecture, as well as training code for those interested in developing audio generation models.
As it stands, it’s looking like we might be on the edge of production-quality AI-generated music with Stable Audio, considering its audio fidelity. Will musicians be happy if they get replaced by AI models? Likely not, if history has shown us anything from AI protests in the visual arts field. For now, a human can easily outclass anything AI can generate, but that may not be the case for long. Either way, AI-generated audio may become another tool in a professional’s audio production toolbox.





