
reader comments
56 with
Things are moving at lightning speed in AI Land. On Friday, a software developer named Georgi Gerganov created a tool called “llama.cpp” that can run Meta’s new GPT-3-class AI large language model, LLaMA, locally on a Mac laptop. Soon thereafter, people worked out how to run LLaMA on Windows as well. Then someone showed it running on a Pixel 6 phone, and next came a Raspberry Pi (albeit running very slowly).
If this keeps up, we may be looking at a pocket-sized ChatGPT competitor before we know it.
But let’s back up a minute, because we’re not quite there yet. (At least not today—as in literally today, March 13, 2023.) But what will arrive next week, no one knows.
Since ChatGPT launched, some people have been frustrated by the AI model’s built-in limits that prevent it from discussing topics that OpenAI has deemed sensitive. Thus began the dream—in some quarters—of an open source large language model (LLM) that anyone could run locally without censorship and without paying API fees to OpenAI.
Open source solutions do exist (such as GPT-J), but they require a lot of GPU RAM and storage space. Other open source alternatives could not boast GPT-3-level performance on readily available consumer-level hardware.
Enter LLaMA, an LLM available in parameter sizes ranging from 7B to 65B (that’s “B” as in “billion parameters,” which are floating point numbers stored in matrices that represent what the model “knows”). LLaMA made a heady claim: that its smaller-sized models could match OpenAI’s GPT-3, the foundational model that powers ChatGPT, in the quality and speed of its output. There was just one problem—Meta released the LLaMA code open source, but it held back the “weights” (the trained “knowledge” stored in a neural network) for qualified researchers only.
leaked the LLaMA weights on BitTorrent. Since then, there’s been an explosion of development surrounding LLaMA. Independent AI researcher Simon Willison has compared this situation to the release of Stable Diffusion, an open source image synthesis model that launched last August. Here’s what he wrote in a post on his blog:
It feels to me like that Stable Diffusion moment back in August kick-started the entire new wave of interest in generative AI—which was then pushed into over-drive by the release of ChatGPT at the end of November.
That Stable Diffusion moment is happening again right now, for large language models—the technology behind ChatGPT itself. This morning I ran a GPT-3 class language model on my own personal laptop for the first time!
AI stuff was weird already. It’s about to get a whole lot weirder.
Typically, running GPT-3 requires several datacenter-class A100 GPUs (also, the weights for GPT-3 are not public), but LLaMA made waves because it could run on a single beefy consumer GPU. And now, with optimizations that reduce the model size using a technique called quantization, LLaMA can run on an M1 Mac or a lesser Nvidia consumer GPU.
Things are moving so quickly that it’s sometimes difficult to keep up with the latest developments. (Regarding AI’s rate of progress, a fellow AI reporter told Ars, “It’s like those videos of dogs where you upend a crate of tennis balls on them. [They] don’t know where to chase first and get lost in the confusion.”)
For example, here’s a list of notable LLaMA-related events based on a timeline Willison laid out in a Hacker News comment:
- February 24, 2023: Meta AI announces LLaMA.
- March 2, 2023: Someone leaks the LLaMA models via BitTorrent.
- March 10, 2023: Georgi Gerganov creates llama.cpp, which can run on an M1 Mac.
- March 11, 2023: Artem Andreenko runs LLaMA 7B (slowly) on a Raspberry Pi 4, 4GB RAM, 10 sec/token.
- March 12, 2023: LLaMA 7B running on NPX, a node.js execution tool.
- March 13, 2023: Someone gets llama.cpp running on a Pixel 6 phone, also very slowly.
- March 13, 2023, 2023: Stanford releases Alpaca 7B, an instruction-tuned version of LLaMA 7B that “behaves similarly to OpenAI’s “text-davinci-003” but runs on much less powerful hardware.
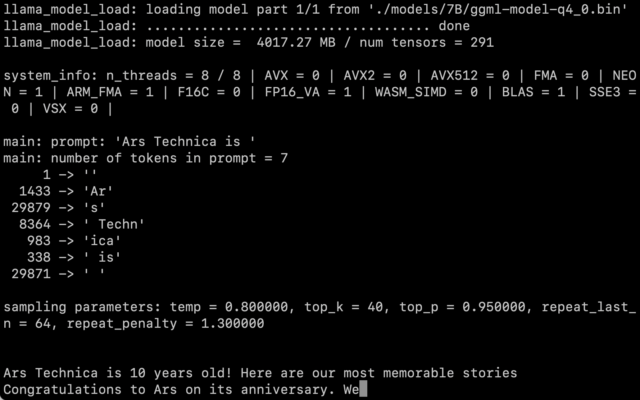
There’s still the question of how much the quantization affects the quality of the output. In our tests, LLaMA 7B trimmed down to 4-bit quantization was very impressive for running on a MacBook Air—but still not on par with what you might expect from ChatGPT. It’s entirely possible that better prompting techniques might generate better results.
Also, optimizations and fine-tunings come quickly when everyone has their hands on the code and the weights—even though LLaMA is still saddled with some fairly restrictive terms of use. The release of Alpaca today by Stanford proves that fine tuning (additional training with a specific goal in mind) can improve performance, and it’s still early days after LLaMA’s release.
As of this writing, running LLaMA on a Mac remains a fairly technical exercise. You have to install Python and Xcode and be familiar with working on the command line. Willison has good step-by-step instructions for anyone who would like to attempt it. But that may soon change as developers continue to code away.
As for the implications of having this tech out in the wild—no one knows yet. While some worry about AI’s impact as a tool for spam and misinformation, Willison says, “It’s not going to be un-invented, so I think our priority should be figuring out the most constructive possible ways to use it.”
Right now, our only guarantee is that things will change rapidly.






