
reader comments
28 with 0 posters participating
On Thursday, a pair of tech hobbyists released Riffusion, an AI model that generates music from text prompts by creating a visual representation of sound and converting it to audio for playback. It uses a fine-tuned version of the Stable Diffusion 1.5 image synthesis model, applying visual latent diffusion to sound processing in a novel way.
Created as a hobby project by Seth Forsgren and Hayk Martiros, Riffusion works by generating sonograms, which store audio in a two-dimensional image. In a sonogram, the X-axis represents time (the order in which the frequencies get played, from left to right), and the Y-axis represents the frequency of the sounds. Meanwhile, the color of each pixel in the image represents the amplitude of the sound at that given moment in time.
Since a sonogram is a type of picture, Stable Diffusion can process it. Forsgren and Martiros trained a custom Stable Diffusion model with example sonograms linked to descriptions of the sounds or musical genres they represented. With that knowledge, Riffusion can generate new music on the fly based on text prompts that describe the type of music or sound you want to hear, such as “jazz,” “rock,” or even typing on a keyboard.
After generating the sonogram image, Riffusion uses Torchaudio to change the sonogram to sound, playing it back as audio.
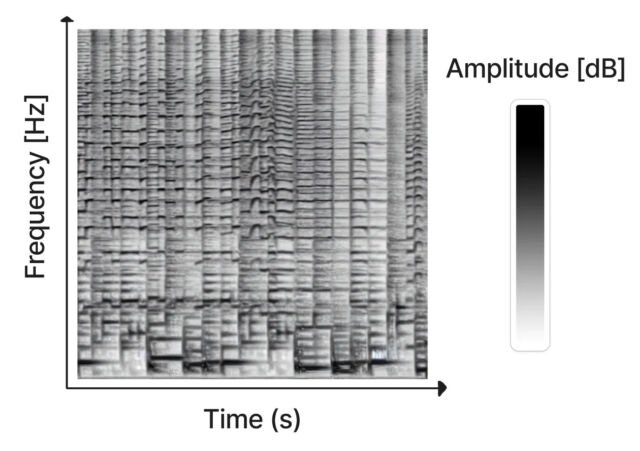
“This is the v1.5 Stable Diffusion model with no modifications, just fine-tuned on images of spectrograms paired with text,” write Riffusion’s creators on its explanation page. “It can generate infinite variations of a prompt by varying the seed. All the same web UIs and techniques like img2img, inpainting, negative prompts, and interpolation work out of the box.”
Visitors to the Riffusion website can experiment with the AI model thanks to an interactive web app that generates interpolated sonograms (smoothly stitched together for uninterrupted playback) in real time while visualizing the spectrogram continuously on the left side of the page.
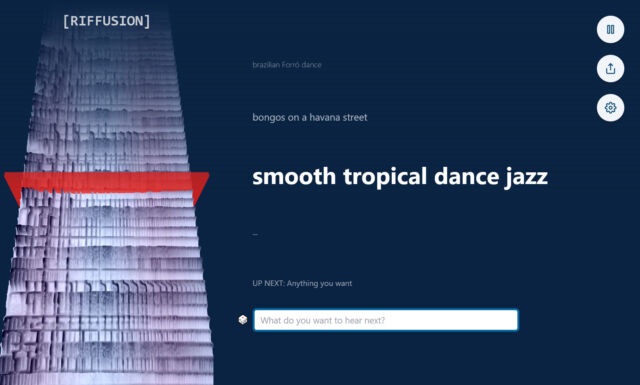
It can fuse styles, too. For example, typing in “smooth tropical dance jazz” brings in elements of different genres for a novel result, encouraging experimentation by blending styles.
Of course, Riffusion is not the first AI-powered music generator. Earlier this year, Harmonai released Dance Diffusion, an AI-powered generative music model. OpenAI’s Jukebox, announced in 2020, also generates new music with a neural network. And websites like Soundraw create music non-stop on the fly.
Compared to those more streamlined AI music efforts, Riffusion feels more like the hobby project it is. The music it generates ranges from interesting to unintelligible, but it remains a notable application of latent diffusion technology that manipulates audio in a visual space.
The Riffusion model checkpoint and code are available on GitHub.






